Turning AI into a Trustworthy Assistant: How I Used RAG to Reduce Hallucinations
About
I built a smart AI tool that helps answer questions from uploaded documents, making it easy for businesses to get accurate info with sources fast.
Anyone who uses AI regularly should notice that sometimes, AI makes things up and delivers it in the most confident tone that makes it hard to doubt it without prior knowledge or fact checking.
But in production, we want AI to actually automate a process or two without us having to check it for errors regularly and having to deal with the embarrassment of providing hallucinated responses to customers or clients.
So how to do this? How to make mister AI agent or mister AI chatbot or any AI app have more accurate data?
You give it less data.
You read that correctly, If your prompt carries a whole document for every answer your chatbot provides, that's not just a lot of unnecessary AI usage that'll add to your bills, that's a lot of data noise that'll cause unspecific answers.
So here's my take on more accurate AI in a simple way and in only a few dozen lines of code. Let's get some RAGs.
Retrieval Augmented Generation (RAG) is a friend you should want to make, and here's why:
I'll be showing how it works in a private website I made.
First, let's upload a file to get answers from, I got the PDF version of the psychology of money:

PDF upload page for RAG
Once it is uploaded, some backend processing happens on the file to make it ready. And then the following page appears:
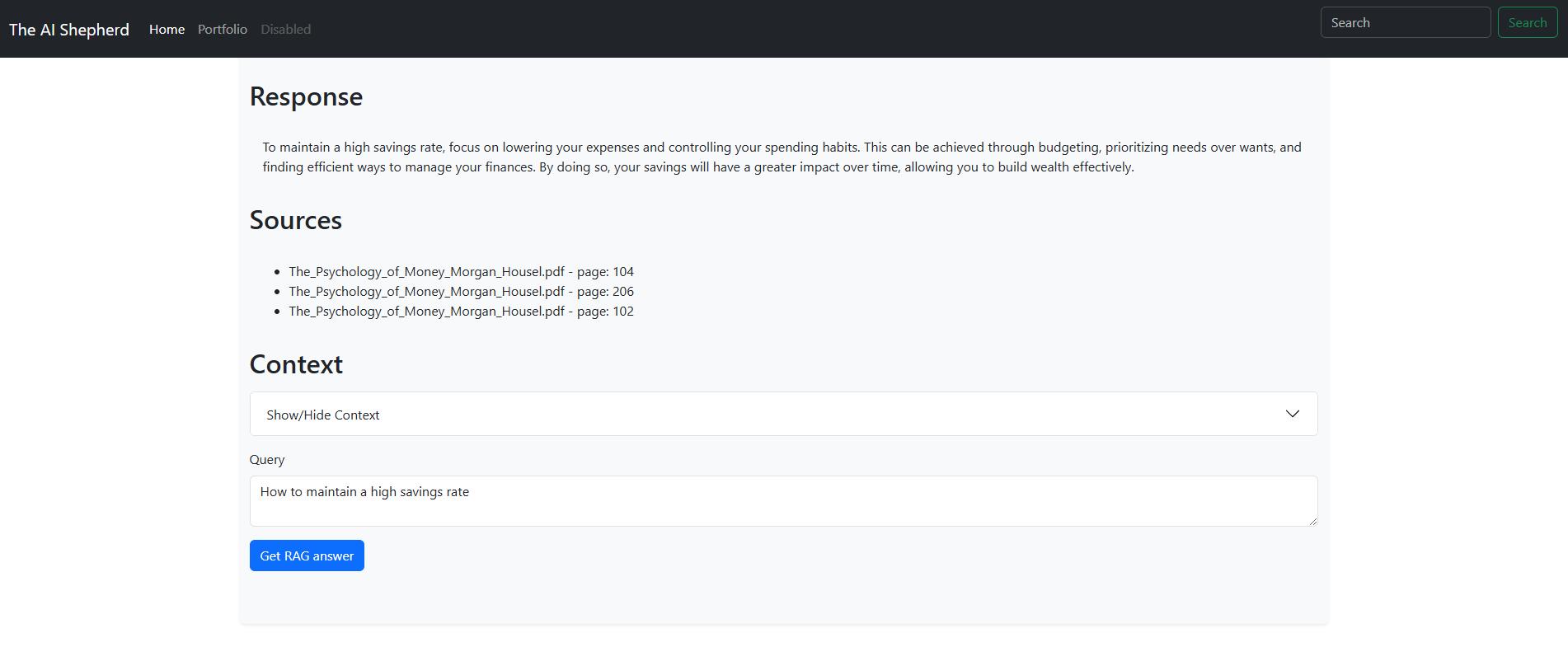
Testing RAG in a website
The best way to explain RAG is to show how it works. In the screenshot above is a form that allows you to ask questions about the uploaded file.
In the "Query" text box, you can ask questions and click the blue button to get answers from the document. Nothing special so far, right ?
However, the answer comes in three parts. We have the response that is quite literally the answer to the question.
Then the sources, showing from which document and which page the answer is deduced from.
And the context is basically the actual pieces of text from the document that were used to answer the question. It's in a spoiler, here's how it looks like :
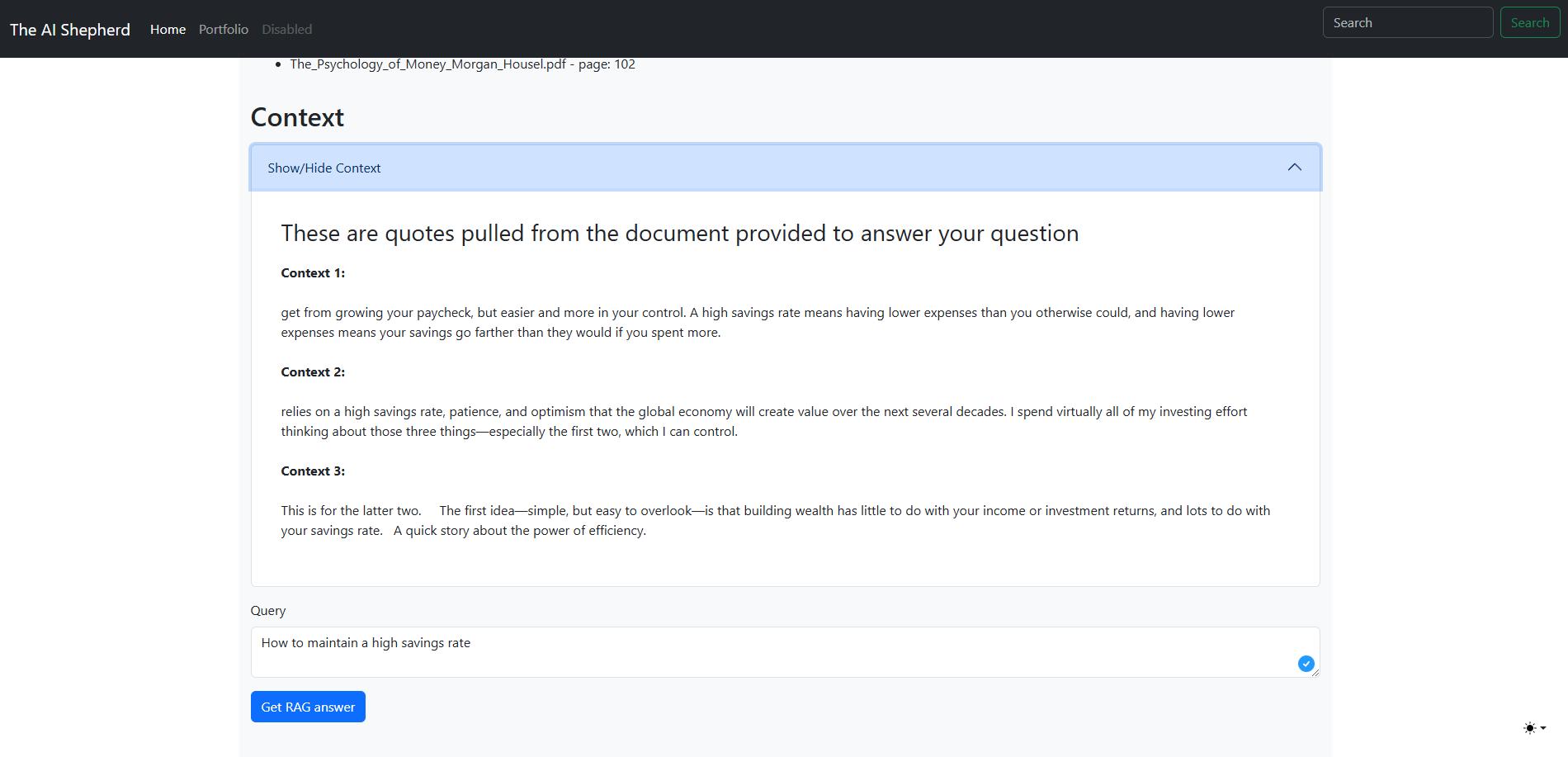
Context used for the response
Without RAG, AI answers from the knowledge base you provide it and from the variance of fish weight in the Atlantic Ocean, learned about in the last OpenAI update.
A mix of relevant and irrelevant data sources doesn't work well for AI accuracy.
It's even more complicated when you have a chatbot in a real estate agency website and a bored teenager comes asking about explosive household materials.
You want your chatbot to say "I don't know" instead of "Here's a list of household explosive materials, how else can I help?"
Kind of like this:
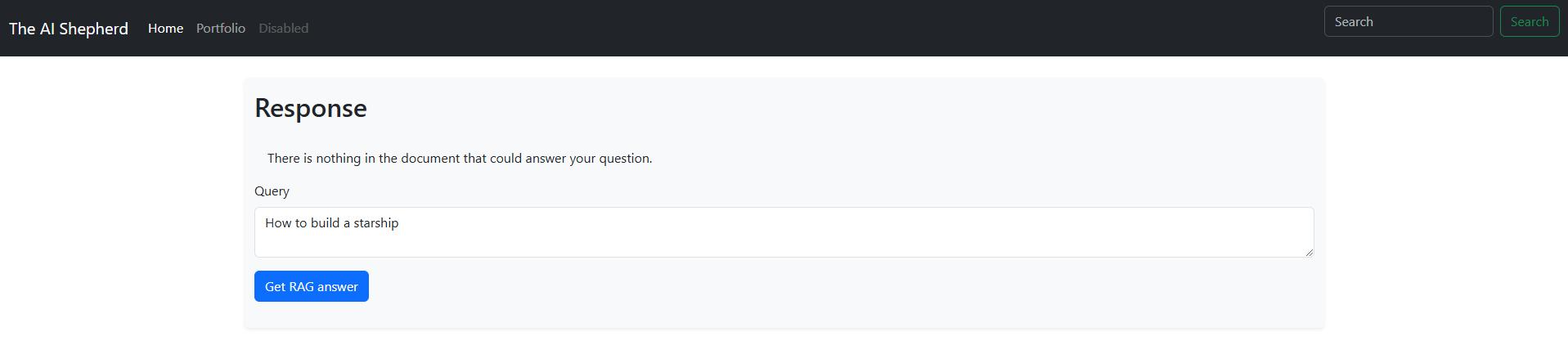
RAG finds no answer
Now let's talk a bit about how it works. Here's the flowchart :
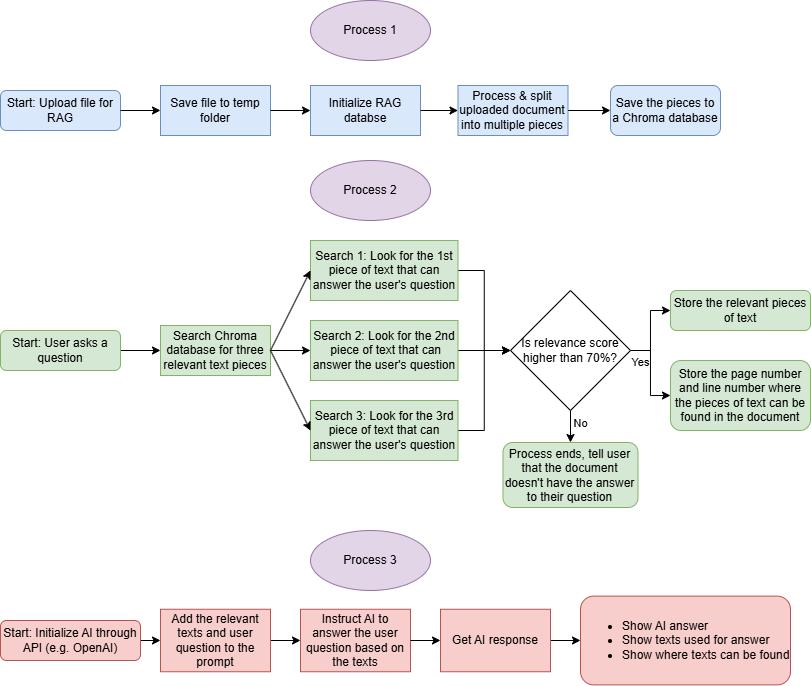
RAG system flowchart
Then below is the code for it all, if you're not into the technical part, you can just stop reading here because below is just going to be a headache. Or you can leave your questions down in the comments.
The secret here is using a database to store the information in the uploaded file as a lot of numbers that contain the meaning of the words and phrases in the document. This is called the vector space.
These numbers are called embeddings, and I used OpenAI's API to get them set up for questioning. These embeddings are stored in a Chroma database using the following code:
def split_text(self, documents: list[Document]):
# Initialize a text splitter with specific chunk size and overlap settings
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=300, # Maximum size of each chunk in characters
chunk_overlap=100, # Overlap between chunks to maintain context
length_function=len, # Function used to measure text length
add_start_index=True, # Include the start index of each chunk in metadata
)
# Split the documents into smaller chunks
self.chunks = text_splitter.split_documents(documents)
# Print the number of documents processed and the total number of chunks created
print(f"Split {len(documents)} documents into {len(self.chunks)} chunks.")
# Select the 10th chunk for inspection (example chunk)
document = self.chunks[10]
# Print the content of the selected chunk
print(document.page_content)
# Print metadata (e.g., source, page number) of the selected chunk
print(document.metadata)
# Return the list of chunks
return self.chunks
def save_to_chroma(self, chunks: list[Document]):
# Clear out the existing Chroma database if it exists
if os.path.exists(self.CHROMA_PATH):
shutil.rmtree(self.CHROMA_PATH) # Remove the existing database directory
# Create a new Chroma database from the provided chunks and embeddings
db = Chroma.from_documents(
chunks, # List of document chunks to be saved
OpenAIEmbeddings(), # Embedding model used for vectorization
persist_directory=self.CHROMA_PATH # Directory where the database is stored
)
# Print a confirmation message showing the number of saved chunks and the directory used
print(f"Saved {len(chunks)} chunks to {self.CHROMA_PATH}.")
Then to process the data stored in the Chroma database, here is the code that finishes the lap and sends a dict with the data to my flask server:
def get_response(self):
# Initialize the embedding function to convert text into vectors
embedding_function = OpenAIEmbeddings()
# Load the Chroma database using the specified persist directory and embedding function
db = Chroma(persist_directory=self.CHROMA_PATH, embedding_function=embedding_function)
# Search the database for the top 3 most relevant chunks based on the query text
results = db.similarity_search_with_relevance_scores(self.query_text, k=3)
# Check if there are no results or if the highest relevance score is below 0.7
if len(results) == 0 or results[0][1] < 0.7:
print(f"Unable to find matching results.") # Print a message if no good match is found
return # Exit the function if no suitable results are available
# Combine the content of the top results into a single context string, separated by "---"
context_text = "\n\n---\n\n".join([doc.page_content for doc, _score in results])
# Create a chat prompt template using the provided template
prompt_template = ChatPromptTemplate.from_template(self.PROMPT_TEMPLATE)
# Format the prompt by inserting the context and the user query
prompt = prompt_template.format(context=context_text, question=self.query_text)
# Print the final formatted prompt (useful for debugging)
print(prompt)
# Extract just the content of the top results into a list for reference
context_texts = [doc.page_content for doc, _score in results]
# Initialize the OpenAI chat model with the specified model version
model = ChatOpenAI(model="gpt-4o-mini")
# Get the model's response by invoking it with the formatted prompt
response_text = model.invoke(prompt)
# Extract sources with their file path and page number from the metadata
sources = [
(doc.metadata.get("source", "unknown"), doc.metadata.get("page", "unknown"))
for doc, _score in results
]
# Format the final response by including the model's response and the source information
self.formatted_response = f"Response: {response_text.content}\nSources: {sources}"
# Return a dictionary containing the response, sources, prompt, and context text
return {"response": response_text.content, "sources": sources, "prompt": prompt, "context": context_texts}
These are class methods, I create objects from them in my flask server code below to show them on the website:
@app.route('/portfolio/RAG/setup', methods=["POST", "GET"])
def rag_setup():
# Initialize the form for file upload
form = RagForm1()
# Check if the form submission is valid (POST request with valid input)
if form.validate_on_submit():
uploaded_file = form.file.data # Get the uploaded file from the form
# Secure the file name to prevent malicious filenames
secured_filename = secure_filename(uploaded_file.filename)
# Save the uploaded file into a temporary folder with a secured name
temp_dir = os.path.join(TEMP_FOLDER, secured_filename)
uploaded_file.save(temp_dir)
# Initialize the RAG database with the temporary folder containing the file
rag_database = RagDatabase(TEMP_FOLDER)
rag_database.prepare() # Prepare the database by processing the uploaded document
# Redirect the user to the action page after setting up the database
return redirect(url_for('rag_action'))
# Render the setup page with the form for file upload
return render_template("RAG.html", form=form)
@app.route('/portfolio/RAG/results', methods=["GET", "POST"])
def rag_action():
# Initialize the form for user query input
form = RagForm2()
# Variables to store response, sources, prompt, and context
response = None
sources = None
prompt = None
context = None
# Check if the form submission is valid (POST request with query input)
if form.validate_on_submit():
query = form.query.data # Get the user query from the form
# Initialize the RAG query with the user's query
rag_query = RagQuery(query)
# Get the response by querying the prepared RAG database
response_dict = rag_query.get_response()
# Try extracting the response and other details from the result dictionary
try:
response = response_dict["response"] # Model's answer to the query
sources = response_dict["sources"] # List of sources used for the answer
prompt = response_dict["prompt"] # Full prompt sent to the model
context = response_dict["context"] # Context used to generate the response
except TypeError:
# Handle the case where no relevant answer is found
response = "There is nothing in the document that could answer your question."
# Render the results page with the form, response, sources, and context
return render_template("RAG_results.html", form=form,
response=response, sources=sources,
prompt=prompt, context=context,
enumerate=enumerate) # Pass enumerate for use in the template
A simple application of RAG may not be enough to show how actually useful it is, but here's three more use cases:
- Customer Support Knowledge Bases: RAG can instantly retrieve relevant information from large collections of internal documents, product manuals, or troubleshooting guides. This reduces response times, improves agent efficiency, and enhances customer satisfaction by providing precise answers.
- Legal Document Analysis: For legal teams dealing with lengthy contracts, case law, or regulations, RAG helps by quickly surfacing the most relevant sections. This speeds up research and reduces the risk of missing critical information during reviews.
- Research and Technical Documentation: In fields like scientific research, engineering, or software development, RAG enables users to query vast archives of papers or technical docs, extracting key insights without manually reading through hundreds of pages.
These use cases showcase how RAG can deliver high ROI by reducing manual effort, speeding up decision-making, and improving accuracy across various industries.
You can try RAG for yourself by clicking the following button: